What Triggers DynamoDB Throttling and Why It Matters
I spent three months last year debugging a production outage where our order processing pipeline suddenly started rejecting writes at 2 AM. Turns out, we’d hit DynamoDB throttling—and I had no idea what that meant beyond “the database said no.”
But what is DynamoDB throttling? In essence, it’s when your application requests exceed the read or write capacity you’ve provisioned. But it’s much more than that. In provisioned mode, you pay for a fixed number of read capacity units (RCU) and write capacity units (WCU) per second. Go over that limit, and requests get rejected with a ProvisionedThroughputExceededException. In on-demand mode, you pay per request, but you still hit soft limits—around 40,000 WCU and 40,000 RCU per second per partition. Uneven key distribution? You’ll throttle way below those numbers.
The real damage stacks fast: failed writes cascade into Lambda dead-letter queues, client timeouts multiply, and customers see “try again later” messages. It’s not just slow—it’s broken.
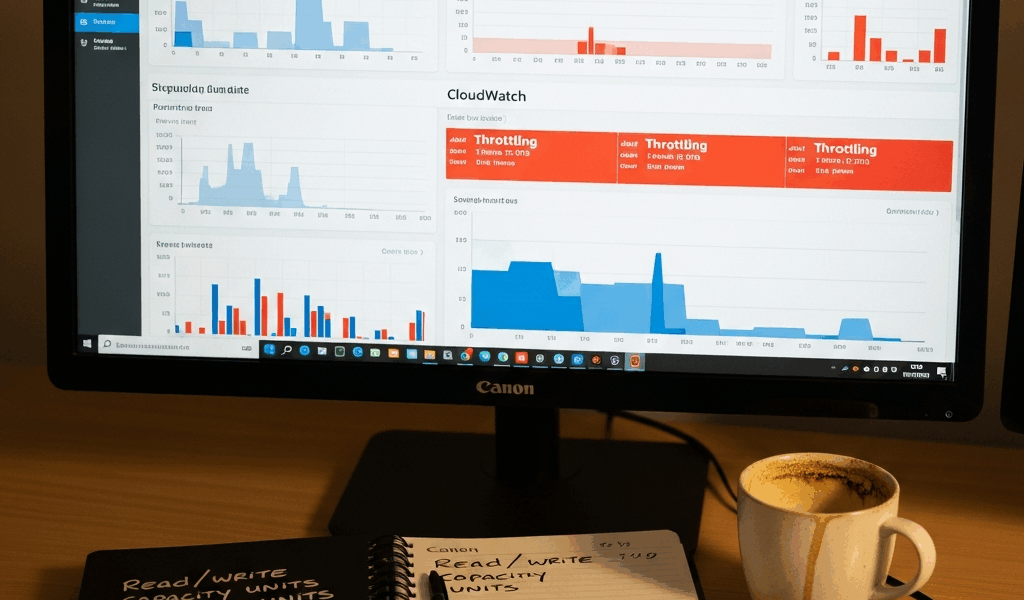
Check CloudWatch Metrics First — Three Things to Look For
Open the CloudWatch console, find your DynamoDB table, and go straight to the Metrics tab. Don’t guess. Look at these three signals.
ConsumedWriteCapacityUnits and ConsumedReadCapacityUnits
These show the actual capacity consumed per second. If you’re provisioned for 100 WCU and the graph spikes to 150, throttling is happening — at least if you’re not using burst capacity. The spike looks like a sudden vertical line. You can’t miss it. Compare the consumed number against your provisioned capacity on the table’s Details tab. If consumed sits at 80% or higher of provisioned for more than a few minutes, autoscaling isn’t keeping pace.
UserErrors Metric
This counts the 4xx exceptions your app is actually hitting. A spike in UserErrors during the same timeframe as high ConsumedWriteCapacityUnits confirms throttling. Flat UserErrors while consumed capacity spikes? That’s a different problem entirely. Check SystemErrors instead.
Throttled Read Requests and Throttled Write Requests
DynamoDB exposes these directly. If either is non-zero, you’re being throttled. Period. These metrics make diagnosis instant.
Probably should have opened with this section, honestly. I wasted hours reading application logs before checking CloudWatch metrics during my first incident.
Provisioned Mode vs On-Demand — How Fixes Differ
Your table runs in one of two billing modes. The fixes are completely different.
Provisioned Mode
You’ve set a static RCU and WCU limit. Throttling here? You have three options:
Enable autoscaling. If you haven’t already, turn on DynamoDB autoscaling in the Capacity tab. Set target utilization to 70% — that’s the AWS default. Autoscaling increases RCU/WCU automatically when you approach that threshold. Takes 1–2 minutes to activate, but it handles predictable spikes nicely. The gotcha: autoscaling has a maximum limit you set (default 40,000 RCU/WCU). Hit that ceiling, and you’re throttled anyway.
Manually increase RCU/WCU. Go to the Capacity tab and edit the provisioned capacity. You can increase instantly, but decreases only happen once per 24-hour period. I increased our order table from 50 to 200 WCU during that 2 AM incident and the throttling stopped within seconds.
Switch to on-demand. If you can’t predict your traffic pattern, flip the billing mode to on-demand. You’ll pay more per request, but no more throttling from capacity limits. The tradeoff: on-demand costs roughly 5–7x more than provisioned at steady state. Only do this if you’re genuinely unpredictable or running a prototype.
On-Demand Mode
You pay per request. Throttling here usually means a hot partition or a terrible query pattern—not insufficient capacity.
Check for hot partitions. If 80% of your writes use the same partition key (or sort key range), you’ll hit the per-partition limits even in on-demand mode. Look at CloudWatch’s ConsumedWriteCapacityUnits by partition key in the DynamoDB Insights console. One partition consuming way more than others? Redistribute your data. Add a random prefix to your partition key or use a sort key that spreads writes across time. Instead of keying by UserId alone, try UserId#ShardId where ShardId is a random number from 1–10.
Replace Scans with Queries. A Scan reads every item in the table. A Query reads only items matching your key condition. Looking for recent orders by user? Switch to Query with a proper sort key. This cuts consumed capacity by 90% sometimes.
Five Quick Fixes to Apply Right Now
1. Enable Autoscaling (Provisioned Only) — 5 Minute Setup
Open DynamoDB console → Your Table → Capacity tab. Click “Edit” and toggle “Autoscaling” on for both Read and Write. Set target utilization to 70%. Set max RCU/WCU to at least 5x your current provisioned capacity — so if you have 100 WCU, set max to 500. Save. Autoscaling takes 2 minutes to activate but handles 95% of organic growth spikes.
2. Redistribute Hot Partitions Using Sort Keys — 30 Minute Fix
Diagnosed a hot partition? Add a shard identifier to your partition key. Instead of:
PK = UserId
Use:
PK = UserId#Shard, SK = Timestamp
where Shard is a random number 1–N. Queries now spread across N partitions instead of hammering one. Migration requires copying data to a new table — use DMS or Lambda batch writes.
3. Replace Scan with Query — Immediate Savings
Find Scan operations in your application code. Grep for “dynamodb.scan” or check CloudWatch Logs Insights. Replace with Query filtered by partition key and sort key. Need to filter by a non-key attribute? Add a GSI (Global Secondary Index) with that attribute as the partition key. A Query on a GSI costs the same as a table Query but hits way less data.
4. Add Burst Capacity Buffer — Zero Cost
DynamoDB reserves 300 seconds of burst capacity per table. Use it. If you’re provisioned for 100 WCU, you can burst to 200 WCU for 300 seconds before throttling. Hitting throttling right at the 300-second mark? Increase provisioned capacity by 20–30% to reduce burst drain speed.
5. Batch Requests Using BatchWriteItem — Code Change
Instead of looping and calling PutItem 100 times, use BatchWriteItem to write 25 items per request. This reduces API calls and spreads the load. Max 25 items per batch, max 16 MB per batch. Example using boto3:
client.batch_write_item(RequestItems={'TableName': [{'PutRequest': {'Item': {...}}}, ...]})
Spot the Root Cause — Queries Scans Partition Keys
Throttling isn’t random. It happens because your access pattern doesn’t match your table design.
Hot Partitions from Uneven Key Distribution
Imagine a logging table keyed by Timestamp. Every log at second 1609459200 goes to the same partition. At the minute boundary — 1609459200, 1609459260, and so on — traffic spikes 10x. Your hot partition gets hammered while others sit empty.
Fix: Add a random shard prefix or hash the timestamp to distribute evenly. Instead of PK = Timestamp, use PK = Hash(Timestamp) % 10. Now each second’s logs spread across 10 partitions.
Scan Operations Reading the Entire Table
A Scan touches every item. If your table has 10 million items and you Scan to find items matching a condition, you’re reading 10 million items worth of capacity even if only 100 match. Replace Scan with Query using proper key design, or create a GSI for frequently scanned attributes.
Query Inefficiency — Reading More Than You Need
A Query that filters 1 million items down to 10 burns capacity for all 1 million reads. Push filters into the partition key or sort key condition instead of post-Query filters. Use ProjectionExpression to fetch only the attributes you actually need.
Throttling happens because someone — usually me — wrote code that reads or writes way more than necessary. Check your queries first. Metrics tell you there’s a problem. Query patterns tell you why.


Stay in the loop
Get the latest team aws updates delivered to your inbox.